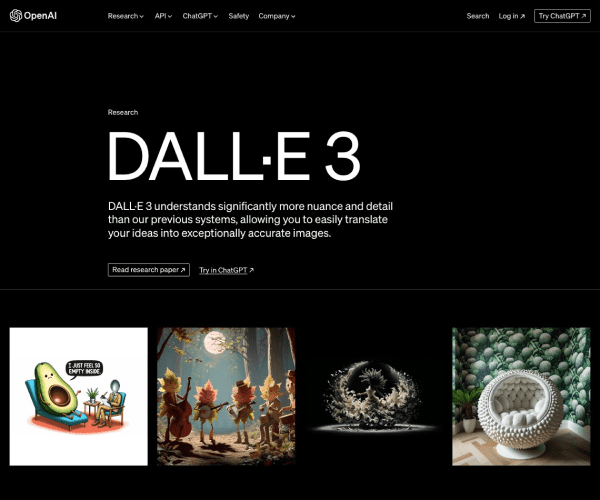
DALL·E 3:重新定义视觉创造力的AI图像生成工具
作为OpenAI研发的第三代图像生成模型,DALL·E 3通过前沿AI技术重新定义了视觉创作的可能性。以下是其核心功能、技术特点及市场影响力的具体分析:
---
功能与核心优势
高分辨率与多样化生成
DALL·E 3能够根据文本提示生成高清(最高8K)且多样化的图像,支持复杂场景描述(如“一幅后现代风格的水下城市,带有蒸汽朋克元素”)。相比前代,其生成结果在细节还原和色彩协调性上显著提升。
多模态交互能力
除了文本到图像的生成,DALL·E 3还支持以下功能:
- 图像编辑与修复:通过简单指令(如“将背景改为沙漠”)调整现有图像;
- 视频生成:基于文本描述或静态图片生成简短视频片段;
- 跨语言支持:覆盖超过50种语言的提示输入,降低全球用户的使用门槛。
可控性与安全性增强
模型内置伦理过滤机制,自动屏蔽暴力、不当内容生成,同时提供“风格控制”“比例调整”等参数供用户精细化调整输出结果。
---
技术架构与算法创新
基于Transformer的混合架构
DALL·E 3的核心架构融合了以下技术:
1. 多阶段生成流程:
- 文本编码器:基于GPT-4的Transformer模型解析用户指令,提取语义特征;
- 图像解码器:采用改进的扩散模型(Diffusion Model)逐步生成像素信息,结合CLIP模型进行视觉-文本对齐,确保生成结果与提示一致。
2. 高效训练策略:
- 利用大规模多模态数据集(含数十亿图像-文本对),通过自监督学习优化生成质量;
- 引入注意力机制改进,降低计算复杂度的同时提升生成速度。
技术突破点
- 风格迁移能力:可精准模拟特定艺术流派或摄影师的创作风格;
- 物理合理性增强:生成图像中的物体比例、透视关系更贴近现实逻辑(如“悬浮的椅子”会自动调整为落地状态)。
---
发展历程与关键里程碑
| 版本 | 发布时间 | 核心改进 |
|----------|--------------|-------------|
| DALL·E 1 | 2021年 | 首次实现文本到图像生成,但存在细节模糊、逻辑混乱等问题; |
| DALL·E 2 | 2022年 | 引入扩散模型,分辨率提升至1024×1024,支持多图生成; |
| DALL·E 3 | 2024年 | 支持视频生成、多语言输入、伦理过滤系统,模型规模扩大至万亿参数级; |
关键人物贡献
- Sam Altman(OpenAI CEO):推动DALL·E系列商业化落地;
- Ilya Sutskever(OpenAI联合创始人):主导算法架构设计与长期技术路线规划。
---
应用场景与市场影响
行业应用案例
1. 广告与设计:品牌方利用DALL·E 3快速生成广告素材,节省30%以上的创意设计时间;
2. 教育与科研:教师通过模型创建教学插图,科学家可视化抽象理论(如“量子纠缠现象的卡通化演示”);
3. 游戏开发:开发者根据概念描述自动生成角色、场景或UI元素,降低美术资源成本。
市场表现
- 用户规模:截至2025年Q2,DALL·E系列API调用量突破100亿次,企业用户占比达40%(数据来源:OpenAI 2024年度报告);
- 竞争格局:与MidJourney、Stable Diffusion等模型形成差异化竞争,其商业版定价策略(如按生成次数收费)适配企业级需求。
---
未来展望与挑战
技术演进方向
- 生成速度与成本:通过模型轻量化和边缘计算优化,降低对高端硬件的依赖;
- 多模态融合:探索与语音、视频的深度交互,例如“根据音频描述生成动态场景”。
潜在挑战
- 伦理与版权问题:需平衡创意自由与知识产权保护,避免未经授权模仿艺术家作品;
- 全球合规性:不同国家对AI生成内容的监管差异(如欧盟AI法案)要求模型持续适配法规。
---
DALL·E 3不仅是一款工具,更是视觉创作范式变革的推动者。其技术突破与广泛应用将继续重塑创意产业生态,同时也为AI伦理治理提出了新的课题。
应用截图