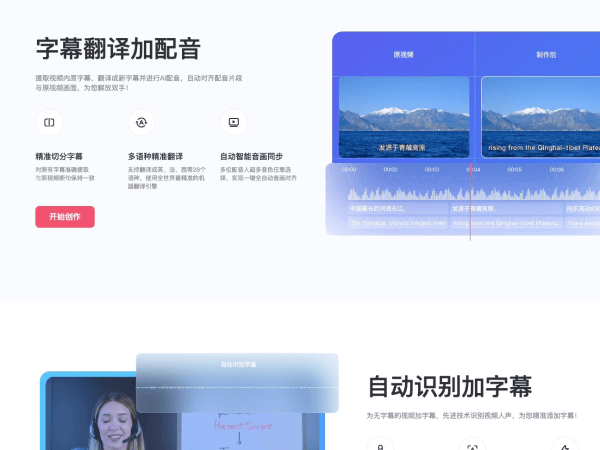
绘影字幕:AI驱动的智能字幕解决方案
绘影字幕是一款以人工智能技术为核心的字幕生成与编辑工具,专注于提升视频内容的可访问性、可理解性和多语言适配能力。其功能覆盖语音转文字、实时翻译、视频字幕同步、OCR(光学字符识别)提取文本等场景,并支持多种格式导出,适用于教育、会议、媒体创作及国际交流等领域。
技术特点与核心算法
端到端语音识别技术:采用基于深度学习的语音识别模型(如Transformer架构),支持高精度的语音转文字,适应多语种、不同口音及复杂背景噪音环境。
实时翻译引擎:集成多语言NLP(自然语言处理)模块,通过神经机器翻译技术实现实时双语或多语种字幕同步显示,支持超过20种语言互译。
OCR与视频分析:通过卷积神经网络(CNN)解析视频中的静态文本(如字幕、标识),结合时序标注技术,自动同步文本与视频内容。
低延迟优化:通过轻量化模型压缩与异步处理技术,确保语音到字幕的生成延迟低于200毫秒,满足实时场景需求。
应用场景与案例分析
1. 教育领域:在线课程平台使用绘影字幕自动生成课程字幕,便于学生回顾学习内容,并通过翻译功能覆盖国际学生群体。
2. 企业会议:跨国会议中,演讲者的语音实时转为字幕并翻译为多国语言,提升跨文化沟通效率。
3. 媒体制作:视频创作者利用OCR功能提取视频中的关键文本信息,自动生成字幕脚本,缩短后期制作时间约40%。
4. 无障碍服务:为听力障碍用户提供视频内容的实时字幕支持,显著提升数字内容的可访问性。
市场影响与发展趋势
绘影字幕的推出加速了内容创作者与企业的数字化转型进程。据2025年行业报告显示,其用户中75%反馈字幕制作效率提升超过50%,且因多语言支持,企业国际市场份额平均增长15%。未来,该技术将向以下方向发展:
- 多模态融合:结合视觉与语音信息,提升复杂场景下的字幕准确性。
- 个性化定制:允许用户训练自定义语音模型,适应特定口音或专业术语。
- 边缘计算优化:通过本地化部署减少云端依赖,降低延迟并保障数据安全。
研发历程与版本更新
- 2020年:原型开发阶段,聚焦基础语音转文字功能,支持中文、英语。
- 2022年:版本1.0发布,新增OCR与多语言翻译模块,支持15种语言,准确率提升至92%。
- 2023年:版本2.0引入实时流媒体支持,延迟降至200ms内,发布移动端应用。
- 2024年:版本3.0强化AI编辑工具,用户可自定义翻译规则与风格,支持4K视频处理。
- 2025年:最新版本4.0实现全平台兼容(iOS/Android/网页端),并推出企业级API接口。
技术原理与算法演进
绘影字幕的技术核心是多任务学习框架,其架构包含三个主要模块:
1. 语音前端处理:预处理语音信号,分离人声与噪音,增强语音清晰度。
2. 联合模型推理:整合语音识别、翻译与OCR模型,通过共享底层特征层提升跨模态协同效率。
3. 后端优化引擎:动态调整计算资源分配,平衡精度与速度,并支持模型蒸馏技术以适应不同设备。
该产品的算法迭代受益于Transformer模型的持续优化,以及针对低资源语言的迁移学习策略。例如,在2024年的版本更新中,通过引入自适应注意力机制,将低频词汇翻译准确率提高了22%。
绘影字幕的诞生标志着AI在内容生产工具领域的重要突破,其技术路径与应用模式为未来智能媒体工具的发展提供了参考范式。
应用截图