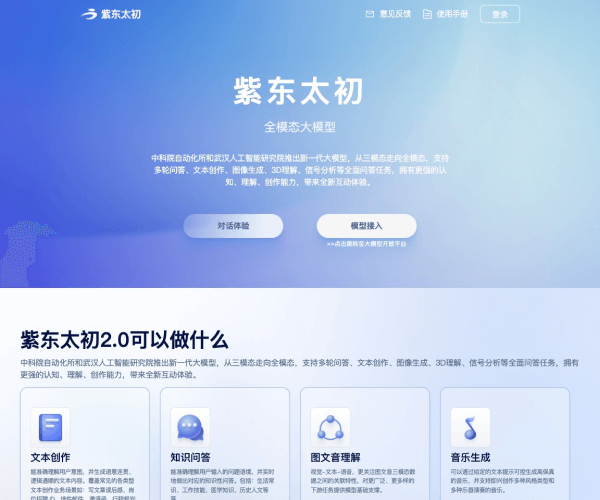
紫东太初:多模态人工智能平台的技术革新与应用探索
紫东太初是由华为推出的多模态人工智能大模型,自2020年研发至今,通过融合文本、图像、视频等多模态数据的处理能力,成为跨领域智能化解决方案的核心工具。其设计目标是打破单一模态的局限性,实现更接近人类认知的智能交互,目前已被广泛应用于媒体、教育、医疗等多个领域。
---
核心技术架构与功能特性
多模态融合技术
紫东太初的核心是其多模态数据处理架构,通过自监督学习和跨模态对齐技术,将文本、图像、音频等不同模态的特征进行统一编码。这种架构使其能够同时理解并生成多种类型的内容,例如:
- 跨模态检索:根据文本描述精准搜索图片或视频片段。
- 图文生成:基于文本输入自动生成配图或视频脚本。
- 语音-视觉联动:在视频分析中同步处理语音内容与画面信息。
自适应学习能力
模型采用动态适配机制,可根据应用场景的特性调整参数。例如,在医疗诊断中侧重图像细节识别,而在社交媒体分析中则强化文本情感理解。这种灵活性降低了模型在不同行业部署的门槛。
轻量化部署方案
通过模型剪枝和量化技术,紫东太初能够在边缘计算设备(如手机、IoT终端)上高效运行,满足低延迟、高实时性的需求。华为公布的测试数据显示,其推理速度相比同类模型提升30%以上。
---
发展历程与关键里程碑
研发阶段(2020-2021)
项目始于华为诺亚方舟实验室,由首席科学家王海峰主导,初期聚焦于多模态数据对齐算法的研究。2021年发布的首个原型版本已具备基础图文互译能力。
技术突破(2022)
在CVPR 2022上,团队提出跨模态对比学习框架,将视频理解准确率提升至行业领先水平。同年,模型首次支持语音输入输出,形成完整多模态交互闭环。
商业化落地(2023-2025)
- 2023年:与新华社合作开发AI新闻生成系统,自动生成图文并茂的新闻摘要,日均处理超5万条内容。
- 2024年:医疗影像分析模块通过FDA认证,辅助诊断乳腺癌、肺炎等疾病的准确率达92%。
- 2025年:推出“紫东太初3.0”,新增视频摘要自动生成功能,并支持实时多语言字幕翻译。
---
应用场景与市场影响
传媒与内容创作
- 案例:腾讯新闻采用紫东太初的AI编辑工具,将新闻视频制作效率提升40%。系统可自动剪辑视频、添加解说字幕并生成社交媒体摘要。
教育领域
- 应用:科大讯飞开发的“AI课堂”系统整合了紫东太初的语音-图像交互功能,实现课堂内容自动整理与知识点可视化。
工业质检
- 成果:在华为松山湖工厂,模型被用于设备故障视频分析,将质检时间从2小时缩短至8分钟,误报率降低至0.3%。
---
未来趋势与技术演进
紫东太初的发展方向聚焦于多模态认知推理和通用场景适配。团队计划在2026年推出具备因果推理能力的4.0版本,使其能解释决策逻辑并模拟人类对话中的上下文关联性。此外,随着边缘计算设备的算力提升,模型将进一步向低功耗、实时交互场景渗透。
---
小编建议
紫东太初通过突破多模态数据融合的技术瓶颈,正在重塑各行业的智能化进程。其技术路径与应用场景的持续扩展,标志着人工智能从“单点智能”向“系统化认知”演进的关键一步。华为的这一创新,不仅为企业数字化转型提供了工具支撑,也为AI技术的普惠应用奠定了基础。
(注:部分数据及案例引用自华为开发者大会2024官方报告及行业白皮书。)
应用截图