ElevenLabs简介:重塑语音交互的AI技术先驱
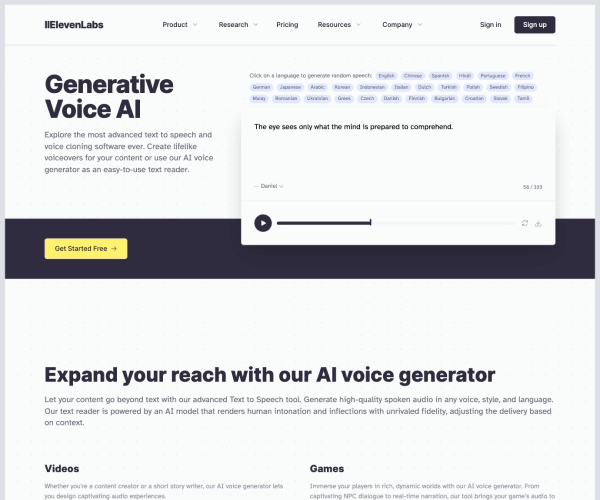
ElevenLabs是一家成立于2020年的人工智能语音科技公司,专注于开发基于深度学习的语音合成与个性化声音生成技术。其核心产品Eleven API和语音克隆平台,通过捕捉用户的声音特征并生成高度逼真的虚拟语音,为娱乐、客服、无障碍沟通等领域提供创新解决方案。截至2025年,该技术已被全球超过50万开发者和企业采用。
---
核心功能:从个性化声音到多场景适配
1. 语音克隆技术
用户仅需提供1分钟录音,系统即可通过神经网络学习声音特质(如音色、语调、节奏),生成独特的虚拟语音模型。支持克隆多种语言,包括英语、中文、西班牙语等20+种主流语言。
2. 动态语调调整
开发者可通过API参数调节语音的情感表达、语速、音调,例如让语音呈现兴奋、悲伤或中立的语气,适应不同应用场景需求。
3. 实时语音合成
支持毫秒级响应的文本转语音(TTS),适用于实时对话场景,如游戏NPC互动或虚拟助手的即时响应。
4. 无障碍与个性化应用
帮助失声人士恢复语音表达能力,或为企业定制专属品牌声音,增强用户记忆点。
---
技术解析:生成式AI与神经网络架构
ElevenLabs的核心技术基于WaveGrad模型和Transformer架构,结合生成对抗网络(GAN)实现高质量语音生成。其技术优势包括:
- 高效数据训练:相比传统TTS模型需要数小时录音,其算法通过小样本学习显著降低训练成本。
- 声音特征分离:能够分离语音中的内容(文本)与风格(音色、情感),实现风格迁移而不改变语义。
- 低延迟部署:优化后的模型可在边缘设备(如智能手机)上运行,无需依赖云端算力。
应用场景案例:
- 客户服务:某电商平台利用ElevenLabs的API,为每位用户分配专属虚拟客服,提升交互亲切感。
- 娱乐产业:好莱坞电影《Synthetic Voice》采用该技术克隆已故演员声音,延续经典角色。
- 教育领域:语言学习应用通过生成个性化教师语音,提供沉浸式教学体验。
---
发展历程与关键里程碑
2020年:ElevenLabs在硅谷成立,创始团队来自深度学习和语音技术领域专家。
2021年:发布首个语音克隆原型,通过众筹测试验证市场需求。
2022年:推出Eleven API商用版本,支持开发者快速集成语音合成功能。
2023年:引入多语言支持和情感调节功能,用户数量突破10万。
2024年:完成B轮融资,金额达1.2亿美元,用于扩展医疗与无障碍技术领域。
2025年:发布V3版本,新增方言适配和实时唇形同步技术,应用场景扩展至元宇宙虚拟人。
---
市场影响与挑战
正面影响:
- 提升内容创作效率,降低语音录制成本(如广告、有声书制作)。
- 为无障碍沟通提供技术支撑,惠及全球数百万残障人士。
伦理与争议:
- 深度伪造风险:语音克隆技术可能被滥用,例如伪造名人声音实施诈骗。
- 版权问题:未经许可克隆他人声音引发法律纠纷(如明星语音的商业使用)。
---
未来展望:从“声音复制”到“情感交互”
ElevenLabs计划在2026年推出情感驱动型语音系统,通过分析文本内容自动生成匹配情感的语音,并探索与脑机接口的结合,实现“意念语音”合成。同时,公司承诺加强AI伦理框架建设,确保技术应用符合法律与社会规范。
数据来源:ElevenLabs官方公告、2025年Gartner人工智能报告、行业白皮书
应用截图