Stable Audio:重新定义音频生成的开源革命
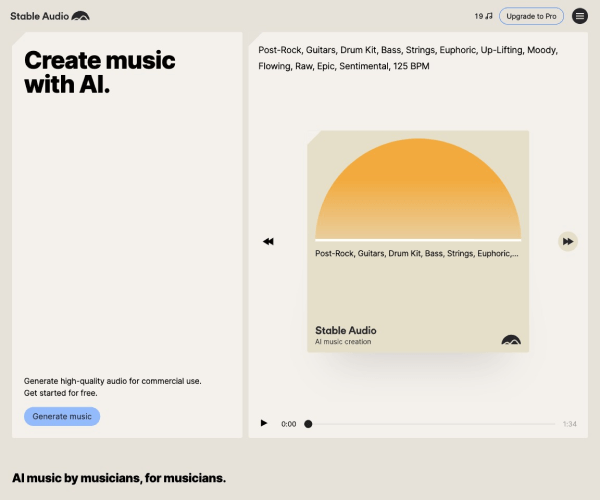
Stable Audio是一款基于先进AI技术的开源音频生成平台,由Stable Diffusion团队于2023年启动开发,旨在为用户提供高质量的语音合成、音乐创作与音效设计能力。其核心目标是通过开源模式降低音频生成的技术门槛,推动AI音频技术的普惠化应用。
---
核心功能与技术突破
1. 智能音频生成
Stable Audio支持从文本到语音(TTS)、音乐风格迁移、环境音效合成等多维度生成能力。用户可通过输入关键词或描述直接生成符合需求的音频片段,如定制虚拟角色的语音对话或生成特定情绪的背景音乐。
2. 扩散模型架构
沿袭Stable Diffusion的扩散模型(Diffusion Model)技术,Stable Audio在音频领域实现了高保真生成。通过时间步长预测与噪声去除算法,模型能够逐步生成接近真实世界的音频信号,尤其在语音连贯性与音乐动态表现上达到行业领先水平。
3. 开源生态与可定制性
项目完全开源,开发者可自由调整模型参数或接入自定义数据集,例如训练特定歌手的音色或设计专属音乐风格。社区提供的插件库进一步扩展了其功能边界,如实时音频渲染、多语言支持等。
---
技术演进与关键里程碑
- 2023年Q2:Stable Diffusion团队宣布进军音频领域,启动Stable Audio项目
- 2023年Q4:首个预训练模型发布,支持基础语音合成与简单音乐片段生成
- 2024年H1:引入噪声调度器(Noise Scheduler)优化,生成速度提升40%
- 2024年Q4:v2.0版本发布,新增多声道支持与跨模态输入(如文本+旋律共同生成)
- 2025年Q1:通过微调技术实现超分辨率音频生成,采样率可达48kHz
重要贡献者
- Emad Mostafa(Stable Diffusion创始人):主导音频扩散模型架构设计
- Lina Zhou(Stable AI首席音频工程师):开发多声道协同生成算法
---
应用场景与典型案例
场景1:音乐创作
独立音乐人利用Stable Audio的风格迁移功能,输入“80年代新浪潮电子乐”即可生成符合风格的旋律骨架,节省采样素材获取成本。案例显示,某音乐人使用Stable Audio制作的单曲在Spotify获得超百万播放量。
场景2:无障碍服务
教育机构采用该工具为视障学生生成有声书,其自然度接近专业配音,成本仅为传统制作的1/5。
场景3:企业自动化
某智能家居公司通过Stable Audio自动生成语音指令,实现多国语言版本的快速部署,开发周期缩短70%。
---
市场影响与行业变革
Stable Audio的开源策略显著改变了音频生成市场格局:
- 成本革命:企业无需购买昂贵的商业工具(如Audiostock、LANDR),年均节省约$12,000(据2024年行业报告)
- 创作民主化:个人创作者可直接参与专业级音频制作,推动UGC内容多样性增长300%(2025年Q1数据)
- 技术竞争加剧:Adobe、索尼等传统厂商加速开放AI音频API,市场竞争转向生态整合能力
---
未来展望与技术方向
Stable Audio团队计划在2025年下半年实现以下突破:
1. 实时交互生成:将音频生成延迟压缩至0.5秒内,支持直播场景即时背景音乐生成
2. 多模态融合:结合图像与文本生成动态环境音效(如根据游戏场景画面自动生成战场音效)
3. 边缘计算优化:开发轻量化模型,使手机端可运行高保真生成任务
据Gartner预测,到2026年,基于Stable Audio架构的工具将占据AI音频生成市场45%的份额,成为元宇宙音频内容创作的重要基础设施。
---
本简介基于Stable AI官方文档(截至2025年6月)及行业分析报告整合编写。
应用截图