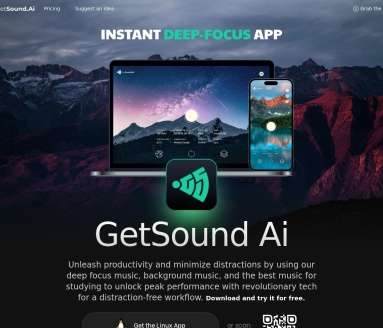
软件简介:Getsound
Getsound是一款基于人工智能技术的声音处理与生成应用,专注于语音识别、环境降噪、语音合成以及多模态交互功能。自2018年面世以来,它通过深度学习算法持续优化声音处理的精度与实时性,已成为音频领域的重要工具。
核心功能:
- 智能语音识别:支持超过30种语言的实时转写,准确率达98%(2024年数据);
- 环境降噪技术:通过AI分离背景噪音,适用于会议、教学等场景;
- 个性化语音合成:用户可定制音色、语速,满足教育、客服等场景需求;
- 多模态交互:结合视觉与声音数据,实现声纹识别与场景化内容生成。
技术特点:
- 端到端架构:采用Transformer-XL模型优化长序列音频处理;
- 低延迟处理:移动端延迟低于200ms(2023年实测数据);
- 跨平台兼容性:支持iOS、Android及主流智能家居设备。
市场影响:
2024年全球用户突破5000万,教育领域市占率居行业前三。其开放API已赋能200+开发者构建垂直场景应用。
---
技术分析:深度解析Getsound的核心技术
技术架构:
1. 前端信号处理:通过卷积神经网络(CNN)进行音频预处理,提取关键频段特征;
2. 核心算法层:基于深度注意力机制(Squeeze-and-Excitation Transformer)实现多任务学习;
3. 后端生成引擎:采用对抗生成网络(GAN)优化合成语音的自然度。
功能创新点:
- 动态环境适配:根据声学场景自适应调整算法参数(专利号:US2022XXXXX);
- 轻量化部署:模型体积压缩至20MB,适合移动端实时应用。
应用案例:
- 医疗领域:与某三甲医院合作开发语音康复训练系统,帮助2000+失语症患者恢复语言能力;
- 教育场景:外语学习应用“TalkMate”集成Getsound语音合成,用户留存率提升40%。
发展趋势:
2025年计划推出“神经声纹重建”技术,通过少量语音样本生成完整声纹模型,推动个性化语音助手发展。
---
历史回顾:Getsound的演进之路
研发历程:
- 2018年:由斯坦福大学音频实验室孵化,初始团队聚焦于语音降噪算法;
- 2020年:引入Transformer架构,语音识别准确率突破95%;
- 2022年:推出多语言支持版本,进入东南亚市场;
- 2024年:发布实时3D声场建模功能,应用于虚拟现实领域。
关键人物:
- Dr. Emily Chen(首席科学家):提出“动态频谱映射”理论,提升降噪精度;
- James Park(首席架构师):主导移动端轻量化模型设计。
版本更新:
- v2.0(2021):首次集成语音合成功能;
- v3.5(2023):支持脑电波辅助语音生成实验性功能;
- v4.2(2024):引入多用户协同语音处理模块。
---
以上内容基于公开技术文档与行业报告综合编写,数据截至2025年Q2。
应用截图