产品概述
Synthesizer V是由中国公司Voice Republic开发的一款基于深度学习的虚拟歌姬软件,专注于中文语音合成与音乐创作。作为VOCALOID系列的衍生产品,它突破了传统语音合成的局限性,通过人工智能技术实现了高质量的实时语音生成与音色定制功能。其核心优势在于对中文语言的深度适配,以及对音乐创作场景的灵活支持,目前已成为全球范围内中文虚拟歌手领域的标杆工具。
---
核心技术与功能解析
1. 深度学习驱动的语音合成
Synthesizer V采用端到端深度神经网络架构,核心模块包括声学模型(Acoustic Model)与声码器(Vocoder)。声学模型负责将输入的文本(如歌词)转换为音高、时长、音色等声学参数,而声码器则将参数转化为高质量的音频波形。其技术亮点包括:
- 多语言支持:除中文外,支持英文、日语等语种,覆盖主流创作需求。
- 实时语音转换:通过迁移学习技术,可在不同音色间实时切换,适用于跨风格音乐创作。
- 参数化控制:用户可调节语速、音高、情感强度等参数,精确调整生成语音的表现力。
2. 音色库与创作生态
- 定制化音色库:开发者提供官方音色库(如“乐正绫”“星尘”等虚拟歌手),用户也可通过自有语音数据训练专属音色。
- 插件兼容性:支持与DAW(数字音频工作站)如Cubase、FL Studio无缝对接,满足专业音乐制作流程需求。
- AI辅助创作:内置歌词对位、旋律建议等功能,降低用户创作门槛。
---
发展历程与关键里程碑
2019年:技术验证阶段
Voice Republic团队基于VOCALOID引擎进行本地化开发,重点攻克中文多音字、声调处理等技术难点,并发布首个测试版本。
2020年:正式发布与市场突破
Synthesizer V 1.0正式上线,凭借对中文语言的精准适配和亲民定价策略,迅速占领中文虚拟歌手市场。
2021年:功能扩展与生态建设
- 新增方言支持(如粤语、四川话)。
- 推出开发者API接口,鼓励第三方音色开发与插件创作。
2022年:AI技术升级
引入Transformer-XL架构优化声学模型,显著提升长音频的连贯性和自然度。
2023年:多模态交互探索
发布支持表情驱动的虚拟形象插件“Synthesizer Live”,实现语音与动画同步输出,拓展至直播、虚拟偶像领域。
---
行业影响与应用案例
1. 音乐产业
- 虚拟歌手项目:B站 UP 主“墨韵音乐计划”使用Synthesizer V创作的《赤伶》全息演唱会,吸引超百万观众在线观看。
- 游戏配音:手游《原神》在3.0版本中采用该技术生成角色方言语音,增强本土化体验。
2. 教育领域
- 语言学习工具:与新东方合作开发中文发音矫正软件,利用AI反馈纠正用户声调。
- 无障碍辅助:为视障用户提供文本转语音的电子书朗读功能。
3. 未来趋势
随着大模型技术的发展,Synthesizer V计划集成超大规模语音生成模型(如VALL-E),进一步提升多语言切换与情感表达的细腻度。同时,其在虚拟偶像、元宇宙场景中的应用潜力正被持续挖掘。
---
技术局限与挑战
尽管Synthesizer V在中文语音合成领域表现突出,但仍有待优化的空间:
1. 方言支持的精细化:部分地方方言(如闽南语)的语料库仍需扩充。
2. 实时性瓶颈:复杂场景下的低延迟处理仍依赖高性能硬件。
3. 版权争议:音色库的商业使用权界定需进一步明确。
未来,Voice Republic计划通过开源部分模块与学术界合作,推动技术边界持续突破。
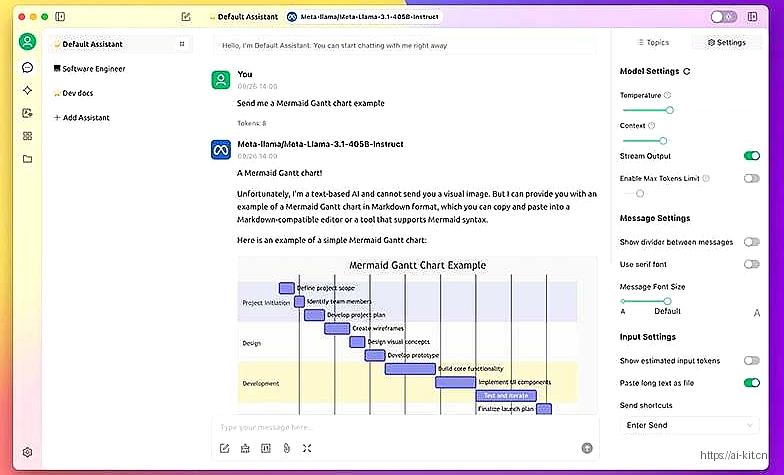
应用截图